背景
为什么做
为了更好地追踪 2025 年涌现的 AI 开源项目,我经常浏览 Github 热榜 并整理分享。但手动查阅难免会有遗漏,为此,我计划开发一套自动化工具来采集 Github 热榜数据,旨在辅助个人技术积累的同时,也为博客内容提供持续的素材来源。下文将详细介绍我的技术实现思路,若有设计不足之处,恳请各位读者指正。
如何制作
在该流程的初始阶段,核心任务是构建针对 GitHub 热榜(Trending)页面的数据采集机制。需要分别按照日(Daily)、周(Weekly)及月(Monthly)三个时间维度,对上榜项目进行结构化抓取。具体实现逻辑及示例代码如下所示:
1import re 2import asyncio 3import random 4from typing import List, Optional 5 6import aiohttp 7from bs4 import BeautifulSoup 8from app.schemas import TrendingRepository 9from app.config import settings 10 11 12class GitHubTrendingCrawler: 13 """简化版GitHub Trending爬虫""" 14 15 def __init__(self): 16 self.base_url = "https://github.com" 17 self.trending_url = settings.github_trending_url 18 self.proxy_url = settings.proxy_url 19 self.user_agents = [ 20 "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36", 21 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36", 22 "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15" 23 ] 24 25 async def fetch_trending( 26 self, 27 language: Optional[str] = None, 28 since: str = "daily", 29 limit: int = 25 30 ) -> List[TrendingRepository]: 31 """获取trending仓库列表""" 32 url = self._build_url(language, since) 33 34 # 创建连接器,配置代理 35 connector = None 36 if self.proxy_url: 37 connector = aiohttp.TCPConnector( 38 ssl=False, # 如果遇到SSL问题,可以设置为False 39 limit=100, 40 limit_per_host=30, 41 ttl_dns_cache=300, 42 use_dns_cache=True, 43 ) 44 45 timeout = aiohttp.ClientTimeout(total=settings.request_timeout) 46 47 async with aiohttp.ClientSession( 48 connector=connector, 49 timeout=timeout 50 ) as session: 51 html_content = await self._fetch_page(session, url) 52 repositories = self._parse_repositories(html_content) 53 54 if limit and len(repositories) > limit: 55 repositories = repositories[:limit] 56 57 return repositories 58 59 def _build_url(self, language: Optional[str], since: str) -> str: 60 """构建trending页面URL""" 61 url = self.trending_url 62 if language: 63 url = f"{url}/{language.lower()}" 64 url = f"{url}?since={since}" 65 return url 66 67 async def _fetch_page(self, session: aiohttp.ClientSession, url: str) -> str: 68 """获取页面HTML内容""" 69 await asyncio.sleep(random.uniform(settings.min_delay, settings.max_delay)) 70 71 headers = { 72 'User-Agent': random.choice(self.user_agents), 73 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8' 74 } 75 76 # 配置请求参数,包含代理 77 request_kwargs = { 78 'headers': headers, 79 'allow_redirects': True, 80 'ssl': False # 如果遇到SSL证书问题 81 } 82 83 # 如果有代理URL,添加到请求参数中 84 if self.proxy_url: 85 request_kwargs['proxy'] = self.proxy_url 86 87 async with session.get(url, **request_kwargs) as response: 88 if response.status != 200: 89 raise Exception(f"HTTP {response.status}") 90 return await response.text() 91 92 # ... 其余方法保持不变 93 def _parse_repositories(self, html_content: str) -> List[TrendingRepository]: 94 """解析HTML内容,提取仓库信息""" 95 soup = BeautifulSoup(html_content, 'html.parser') 96 repositories = [] 97 98 for article in soup.find_all('article', class_='Box-row'): 99 try: 100 repo = self._parse_single_repository(article) 101 if repo: 102 repositories.append(repo) 103 except Exception: 104 continue 105 106 return repositories 107 108 def _parse_single_repository(self, article) -> TrendingRepository: 109 """解析单个仓库信息""" 110 # 获取仓库名称和URL 111 title = article.find('h2', class_='h3 lh-condensed') 112 link = title.find('a') if title else None 113 repo_path = link.get('href', '').strip() if link else None 114 115 if not repo_path: 116 return None 117 118 repo_url = f"https://github.com{repo_path}" 119 repo_name = repo_path.strip('/') 120 owner, repo_short_name = repo_name.split('/', 1) 121 122 # 获取描述 123 desc = article.find('p', class_='col-9') 124 description = desc.get_text(strip=True) if desc else None 125 126 # 获取编程语言 127 lang = article.find('span', itemprop='programmingLanguage') 128 language = lang.get_text(strip=True) if lang else None 129 130 # 获取星标和fork 131 stars, forks = self._parse_stats(article) 132 133 # 获取今日星标数 134 stars_today = self._parse_stars_today(article) 135 136 # 获取头像URL 137 avatar_url = f"https://avatars.githubusercontent.com/{owner}?v=4" 138 139 return TrendingRepository( 140 name=repo_name, 141 url=repo_url, 142 description=description, 143 stars=stars, 144 forks=forks, 145 language=language, 146 stars_today=stars_today, 147 owner=owner, 148 repo_name=repo_short_name, 149 avatar_url=avatar_url 150 ) 151 152 def _parse_stats(self, article) -> tuple[int, int]: 153 """解析星标数和fork数""" 154 stars, forks = 0, 0 155 for link in article.find_all('a', class_='Link--muted'): 156 href = link.get('href', '') 157 text = link.get_text(strip=True) 158 159 if '/stargazers' in href: 160 stars = self._parse_number(text) 161 elif '/forks' in href: 162 forks = self._parse_number(text) 163 return stars, forks 164 165 def _parse_stars_today(self, article) -> int: 166 """解析今日新增星标数""" 167 star_text = article.find('span', class_='d-inline-block float-sm-right') 168 if star_text: 169 text = star_text.get_text(strip=True) 170 match = re.search(r'(\d+)\s+stars?\s+today', text) 171 if match: 172 return int(match.group(1).replace(',', '')) 173 return 0 174 175 def _parse_number(self, text: str) -> int: 176 """解析数字字符串""" 177 if not text: 178 return 0 179 text = text.replace(',', '').lower() 180 181 if text.endswith('k'): 182 return int(float(text[:-1]) * 1000) 183 elif text.endswith('m'): 184 return int(float(text[:-1]) * 1000000) 185 186 try: 187 return int(float(text)) 188 except (ValueError, TypeError): 189 return 0 190 191 async def get_supported_languages(self) -> List[str]: 192 """获取支持的编程语言列表""" 193 return [ 194 'python', 'javascript', 'java', 'typescript', 'c++', 'c', 'c#', 195 'go', 'rust', 'php', 'ruby', 'swift', 'kotlin', 'dart', 'scala', 196 'r', 'matlab', 'shell', 'html', 'css', 'vue', 'react', 'angular' 197 ] 198 199 200# 使用示例 201async def main(): 202 # 替换为你的Trojan代理地址和端口 203 proxy_url = "http://127.0.0.1:1080" # 或者 "socks5://127.0.0.1:1080" 204 205 crawler = GitHubTrendingCrawler(proxy_url=proxy_url) 206 207 try: 208 repos = await crawler.fetch_trending(language="python", since="daily", limit=10) 209 for repo in repos: 210 print(f"{repo.name} - {repo.stars} stars") 211 except Exception as e: 212 print(f"Error: {e}") 213 214if __name__ == "__main__": 215 asyncio.run(main()) 216
目前爬虫面临的主要局限在于抓取内容的原始性。仅能提取包括项目名称、地址、星标数及描述在内的基础 JSON 格式数据。这类数据缺乏多维度的分析价值,需进行后续的处理以提升数据的可用性和业务洞察力。
1 { 2 "name": "sansan0/TrendRadar", 3 "url": "https://github.com/sansan0/TrendRadar", 4 "description": "🎯 告别信息过载,AI 助你看懂新闻资讯热点,简单的舆情监控分析 - 多平台热点聚合+基于 MCP 的AI分析工具。监控35个平台(抖音、知乎、B站、华尔街见闻、财联社等),智能筛选+自动推送+AI对话分析(用自然语言深度挖掘新闻:趋势追踪、情感分析、相似检索等13种工具)。支持企业微信/个人微信/飞书/钉钉/Telegram/邮件/ntfy/bark 推送,30秒网页部署,1分钟手机通知,无需编程。支持Docker部署⭐ 让算法为你服务,用AI理解热点", 5 "stars": 27648, 6 "forks": 15017, 7 "language": "Python", 8 "stars_today": 573, 9 "owner": "sansan0", 10 "repo_name": "TrendRadar", 11 "avatar_url": "https://avatars.githubusercontent.com/sansan0?v=4", 12 "img_url": null, 13 "cached_at": "2025-11-25 15:57:12.573849" 14 } 15
鉴于部分 GitHub 项目的内容呈现较为晦涩,难以通过概览即刻洞察其核心功能与应用场景,需要利用大语言模型(LLM)对项目进行 AI 总结。在通过精炼的概述,读者能够迅速掌握项目精髓,提升信息获取效率。针对该目标的 GitHub 项目总结提示词(Prompt)设计如下:
1请为以下GitHub项目生成一句简洁的中文总结,突出项目亮点和价值,给定github信息为JSON格式, 2要求: 31. 一句话总结,不超过200字,不要有特殊字符 42. 突出项目核心价值和技术亮点 53. 使用简洁易懂的中文描述 64. 除了总结,不要输出其他内容 75. 不要输出目前都多少颗星 86. 内容适合做口播文案使用 9 10内容如下: 11{{ content }} 12
每期项目也要给出汇总的概况,也可以交给大模型去完成,比如使用以下提示词总结本期项目:
1请为以下JSON格式的GitHub热榜项目进行250字的整体趋势总结,突出本期项目的技术热点: 2 3要求: 41. 用中文简洁总结,不超过250中文字符,使用一段话,不换行,不要有特殊符号 52. 突出技术趋势和热点领域 63. 总结核心特点和行业洞察 74. 使用积极准确的表达,避免模糊表述 85. 除了总结不要输入其他内容 96. 生成总结适合微信公众号风格: 技术性、问题导向、代码为主;技术教程、问题解决、开发经验;可复现、能解决实际问题 10 11JSON格式的GitHub热榜项目数据: 12 {{ content }} 13
在个人阅读场景下,基础的 GitHub 项目筛选流程已足以满足需求。然而,针对自媒体内容发布,图文并茂的展示形式更为友好。为了提升配图效率,工作流经历了从最初费时费力的“手动截图”,到尝试使用 Playwright 自动化截图项目主页(存在耗时久、依赖重的问题),最终借助大模型方案,采用了直接获取 GitHub 原生 Open Graph 社交卡片的方法。该方案无需额外依赖,获取速度快且稳定性高,实现了高效自动化的项目配图。
1)}/{user}/{repo}) 2
在完成所有前置步骤后,整个流程进入了组装阶段。核心任务是利用 Python 运行程序以实现按需或定时执行,并确保数据能够自动获取。初期尝试使用“影刃”工具进行定时调度并发送报告,但这要求宿主电脑保持常开状态,存在一定局限性。随后转而采用 n8n 自动化平台,虽然该工具具有一定的上手门槛,但配置完成后能极大提升效率与便捷性。下图展示了基于 n8n 构建的工作流示例,仅供参考。
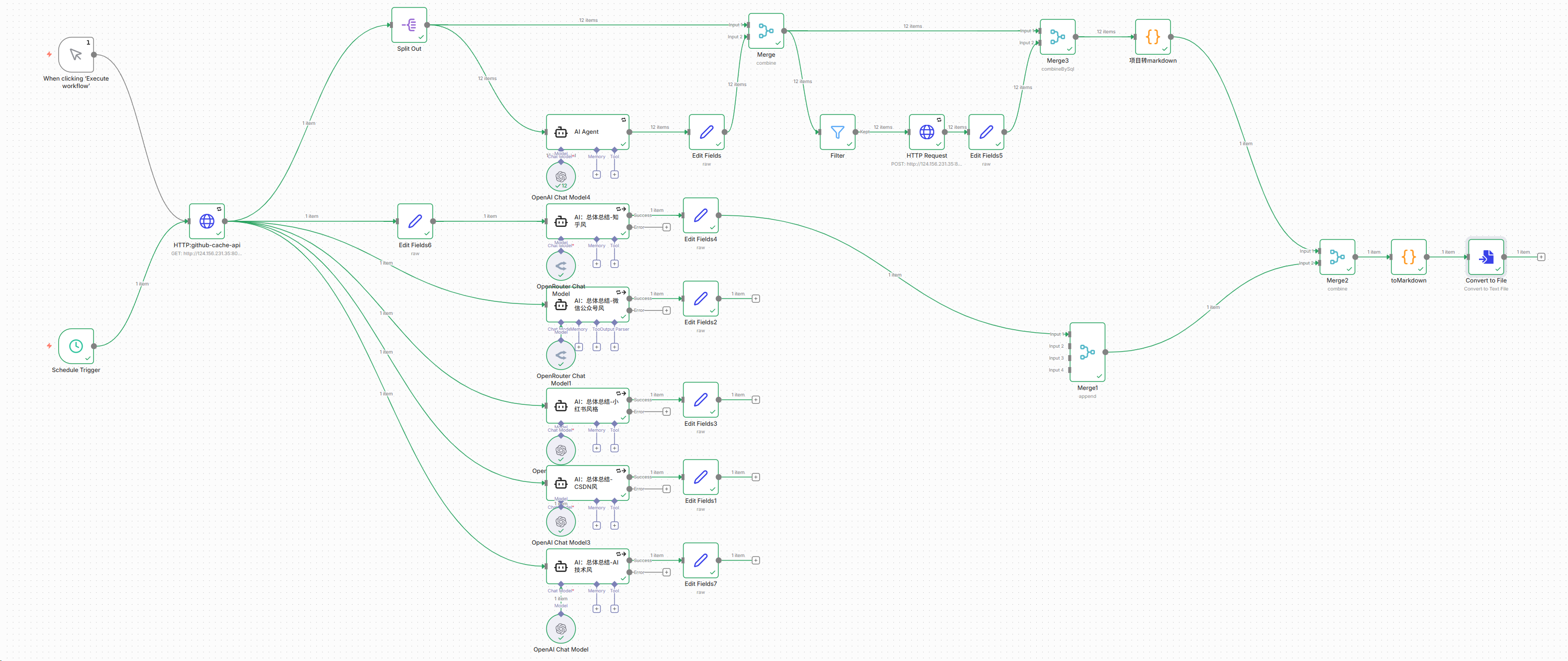
下面就是使用 n8n 工作流总结的 2025 年 12 月份 Github 最热门项目总结,仅供阅读。
效果展示:GitHub 热榜项目 - 月榜(2025-12)
生成于:2026-1-1
统计摘要
共发现热门项目: 18 个
榜单类型:月榜
本期热点趋势总结
本期热榜项目揭示了AI原生开发工具的强劲势头,特别是围绕大型语言模型构建记忆与状态管理系统的趋势。通过AI智能压缩和注入会话上下文,这类工具旨在突破LLM固有的上下文窗口限制,实现跨会话的持续性智能协作。这不仅反映了开发者对深度集成AI于编程工作流的迫切需求,也预示着AI智能体正从单一交互向具备长期记忆的复杂协作伙伴演进,推动着下一代开发范式的形成。

1. thedotmack/claude-mem
- 🏷️ 项目名称: thedotmack/claude-mem
- 🔗 项目地址: https://github.com/thedotmack/claude-mem
- ⭐ 当前 Star 数: 9780
- 📈 趋势 Star 数: 9307
- 📋 项目介绍: A Claude Code plugin that automatically captures everything Claude does during your coding sessions, compresses it with AI (using Claude’s agent-sdk), and injects relevant context back into future sessions.
- 💡 推荐语: 专为Claude Code设计的智能记忆插件能自动记录编程过程并用AI压缩储存再将相关上下文精准注入新会话显著提升开发效率

2. basecamp/fizzy
- 🏷️ 项目名称: basecamp/fizzy
- 🔗 项目地址: https://github.com/basecamp/fizzy
- ⭐ 当前 Star 数: 6435
- 📈 趋势 Star 数: 6435
- 📋 项目介绍: Kanban as it should be. Not as it has been.
- 💡 推荐语: 这款Ruby开发的Kanban工具重新定义了项目管理,告别复杂拥抱简洁高效
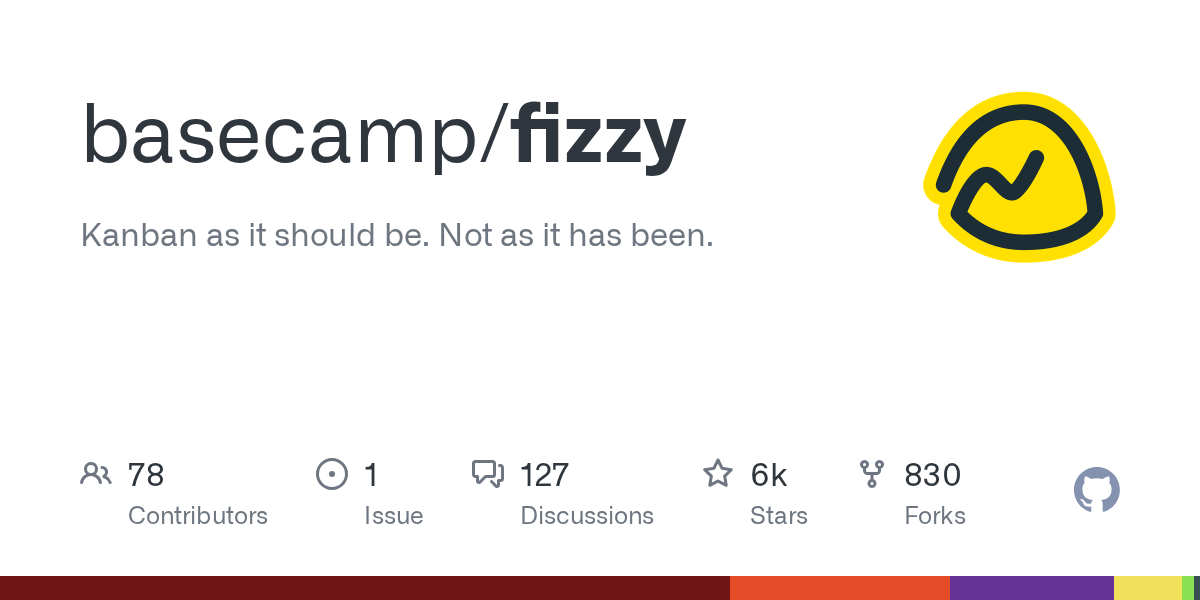
3. DayuanJiang/next-ai-draw-io
- 🏷️ 项目名称: DayuanJiang/next-ai-draw-io
- 🔗 项目地址: https://github.com/DayuanJiang/next-ai-draw-io
- ⭐ 当前 Star 数: 15948
- 📈 趋势 Star 数: 14988
- 📋 项目介绍: A next.js web application that integrates AI capabilities with draw.io diagrams. This app allows you to create, modify, and enhance diagrams through natural language commands and AI-assisted visualization.
- 💡 推荐语: 这款基于Next.js和AI的绘图工具让你能用自然语言轻松创建和编辑专业图表。
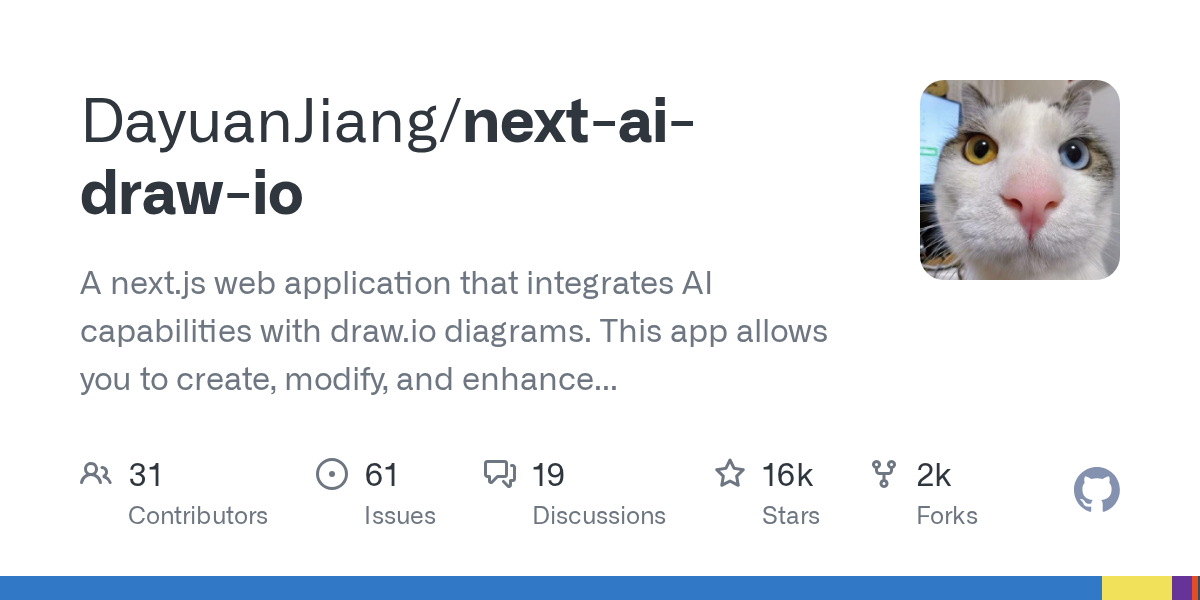
4. exo-explore/exo
- 🏷️ 项目名称: exo-explore/exo
- 🔗 项目地址: https://github.com/exo-explore/exo
- ⭐ 当前 Star 数: 39116
- 📈 趋势 Star 数: 6581
- 📋 项目介绍: Run your own AI cluster at home with everyday devices 📱💻 🖥️⌚
- 💡 推荐语: Exo让你用闲置手机电脑手表组建家庭AI集群,用Python轻松搭建分布式智能计算网络。
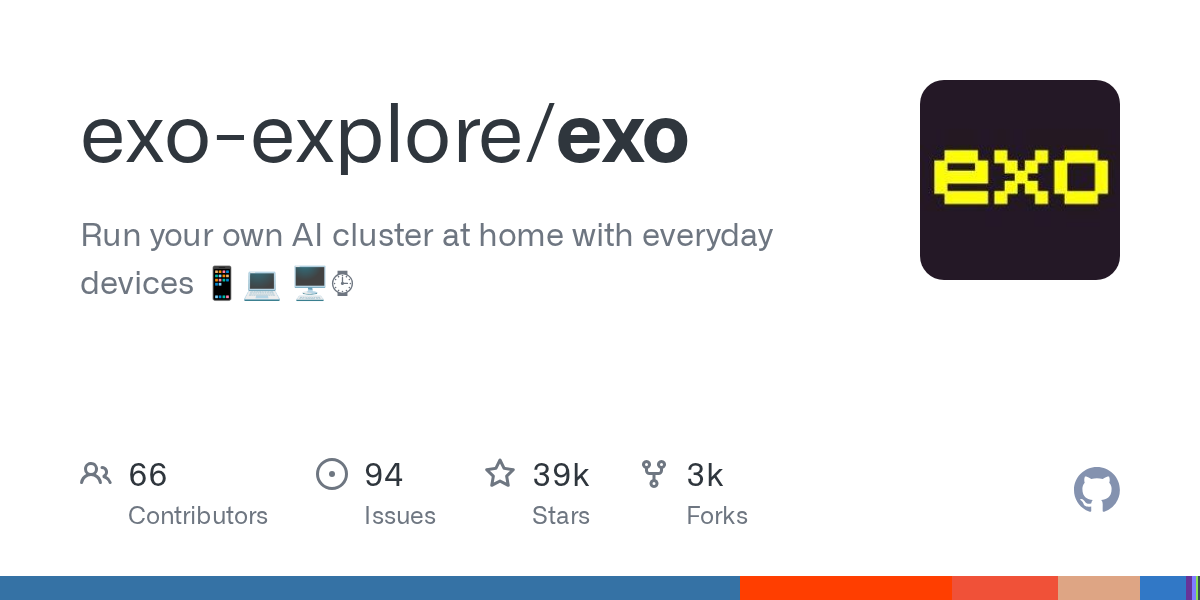
5. datawhalechina/hello-agents
- 🏷️ 项目名称: datawhalechina/hello-agents
- 🔗 项目地址: https://github.com/datawhalechina/hello-agents
- ⭐ 当前 Star 数: 13647
- 📈 趋势 Star 数: 8522
- 📋 项目介绍: 📚 《从零开始构建智能体》——从零开始的智能体原理与实践教程
- 💡 推荐语: 《从零开始构建智能体》开源教程:手把手教你用Python实践AI智能体核心原理,轻松开启人工智能技术大门。
6. simstudioai/sim
- 🏷️ 项目名称: simstudioai/sim
- 🔗 项目地址: https://github.com/simstudioai/sim
- ⭐ 当前 Star 数: 24777
- 📈 趋势 Star 数: 6312
- 📋 项目介绍: Open-source platform to build and deploy AI agent workflows.
- 💡 推荐语: 一款开源的TypeScript AI智能体工作流平台,助你轻松构建和部署自动化AI应用
7. sst/opencode
- 🏷️ 项目名称: sst/opencode
- 🔗 项目地址: https://github.com/sst/opencode
- ⭐ 当前 Star 数: 44974
- 📈 趋势 Star 数: 10579
- 📋 项目介绍: The open source coding agent.
- 💡 推荐语: SST OpenCode是用TypeScript构建的开源AI编程助手,能自动化执行编码任务提升开发者效率。

8. resemble-ai/chatterbox
- 🏷️ 项目名称: resemble-ai/chatterbox
- 🔗 项目地址: https://github.com/resemble-ai/chatterbox
- ⭐ 当前 Star 数: 19993
- 📈 趋势 Star 数: 5152
- 📋 项目介绍: SoTA open-source TTS
- 💡 推荐语: Resemble AI开源的Chatterbox项目,提供了最前沿的文本转语音技术,让开发者能够轻松打造自然流畅的语音交互应用。
9. rustfs/rustfs
- 🏷️ 项目名称: rustfs/rustfs
- 🔗 项目地址: https://github.com/rustfs/rustfs
- ⭐ 当前 Star 数: 18796
- 📈 趋势 Star 数: 7128
- 📋 项目介绍: 🚀2.3x faster than MinIO for 4KB object payloads. RustFS is an open-source, S3-compatible high-performance object storage system supporting migration and coexistence with other S3-compatible platforms such as MinIO and Ceph.
- 💡 推荐语: RustFS开源高性能对象存储比MinIO快2.3倍,兼容S3协议并支持与MinIO、Ceph无缝迁移共存。
10. Tencent/WeKnora
- 🏷️ 项目名称: Tencent/WeKnora
- 🔗 项目地址: https://github.com/Tencent/WeKnora
- ⭐ 当前 Star 数: 10714
- 📈 趋势 Star 数: 3051
- 📋 项目介绍: LLM-powered framework for deep document understanding, semantic retrieval, and context-aware answers using RAG paradigm.
- 💡 推荐语: 腾讯开源WeKnora,一个基于RAG和大语言模型的智能文档理解框架,能深度解析文档语义并精准检索,帮助用户快速获取关键信息。

11. agentsmd/agents.md
- 🏷️ 项目名称: agentsmd/agents.md
- 🔗 项目地址: https://github.com/agentsmd/agents.md
- ⭐ 当前 Star 数: 13692
- 📈 趋势 Star 数: 5029
- 📋 项目介绍: AGENTS.md — a simple, open format for guiding coding agents
- 💡 推荐语: agentsmd推出开源AGENTSMD协议,用TypeScript定义标准化格式,让编程AI代理协作更高效规范
12. anthropics/claude-quickstarts
- 🏷️ 项目名称: anthropics/claude-quickstarts
- 🔗 项目地址: https://github.com/anthropics/claude-quickstarts
- ⭐ 当前 Star 数: 13068
- 📈 趋势 Star 数: 2605
- 📋 项目介绍: A collection of projects designed to help developers quickly get started with building deployable applications using the Claude API
- 💡 推荐语: Anthropic官方出品的Claude API快速入门宝典,提供Python实战项目合集,助你零基础快速构建可部署的AI应用
13. trustedsec/social-engineer-toolkit
- 🏷️ 项目名称: trustedsec/social-engineer-toolkit
- 🔗 项目地址: https://github.com/trustedsec/social-engineer-toolkit
- ⭐ 当前 Star 数: 14281
- 📈 趋势 Star 数: 1634
- 📋 项目介绍: The Social-Engineer Toolkit (SET) repository from TrustedSec - All new versions of SET will be deployed here.
- 💡 推荐语: TrustedSec开源的社会工程学工具包,用Python打造专业级渗透测试框架,助你深度理解并防范网络钓鱼等安全威胁。
14. cocoindex-io/cocoindex
- 🏷️ 项目名称: cocoindex-io/cocoindex
- 🔗 项目地址: https://github.com/cocoindex-io/cocoindex
- ⭐ 当前 Star 数: 5547
- 📈 趋势 Star 数: 2088
- 📋 项目介绍: Data transformation framework for AI. Ultra performant, with incremental processing. 🌟 Star if you like it!
- 💡 推荐语: cocoindex是一款用Rust构建的AI数据转换框架,具备卓越性能和增量处理能力,让数据处理效率倍增。
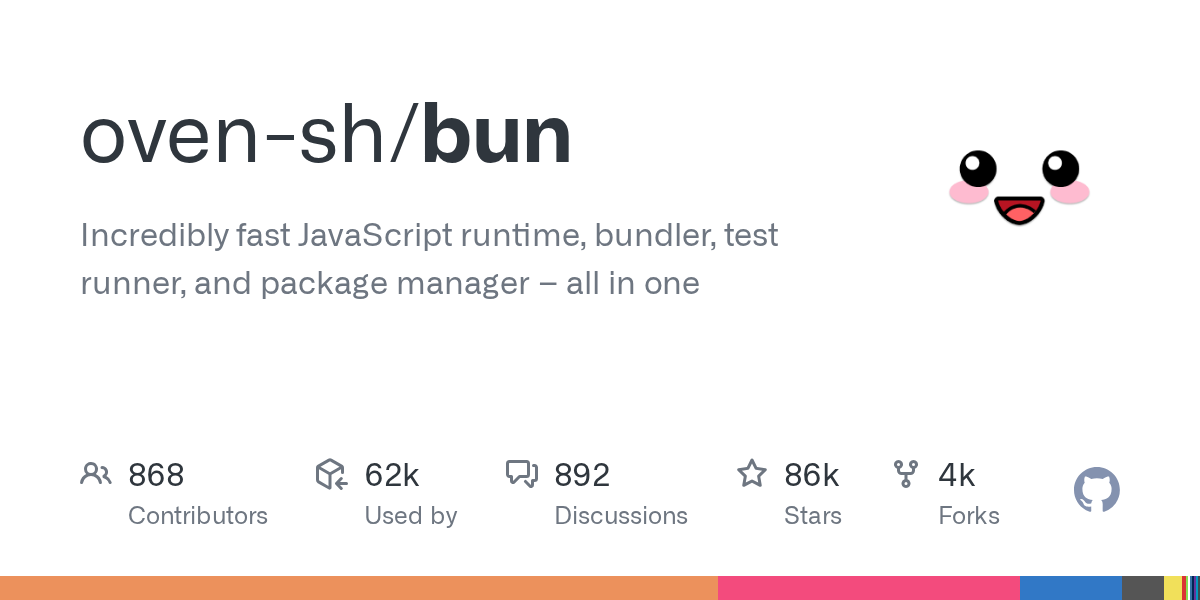
15. oven-sh/bun
- 🏷️ 项目名称: oven-sh/bun
- 🔗 项目地址: https://github.com/oven-sh/bun
- ⭐ 当前 Star 数: 85829
- 📈 趋势 Star 数: 3579
- 📋 项目介绍: Incredibly fast JavaScript runtime, bundler, test runner, and package manager – all in one
- 💡 推荐语: Bun是一款革命性的一体化JavaScript工具集,用Zig语言编写,以极致速度重新定义了JavaScript运行时、打包器、测试运行器和包管理器。
16. anthropics/claude-code
- 🏷️ 项目名称: anthropics/claude-code
- 🔗 项目地址: https://github.com/anthropics/claude-code
- ⭐ 当前 Star 数: 50164
- 📈 趋势 Star 数: 6300
- 📋 项目介绍: Claude Code is an agentic coding tool that lives in your terminal, understands your codebase, and helps you code faster by executing routine tasks, explaining complex code, and handling git workflows - all through natural language commands.
- 💡 推荐语: Anthropic推出的Claude Code是终端智能编程助手,通过自然语言理解代码库并自动执行编程任务、解释复杂代码和管理Git工作流,大幅提升开发效率。

17. danielmiessler/Personal_AI_Infrastructure
- 🏷️ 项目名称: danielmiessler/Personal_AI_Infrastructure
- 🔗 项目地址: https://github.com/danielmiessler/Personal\_AI\_Infrastructure
- ⭐ 当前 Star 数: 2790
- 📈 趋势 Star 数: 1610
- 📋 项目介绍: Personal AI Infrastructure for upgrading humans.
- 💡 推荐语: 这个TypeScript项目为你打造个人专属的AI基建,旨在全方位提升你的信息处理能力和个人效率。

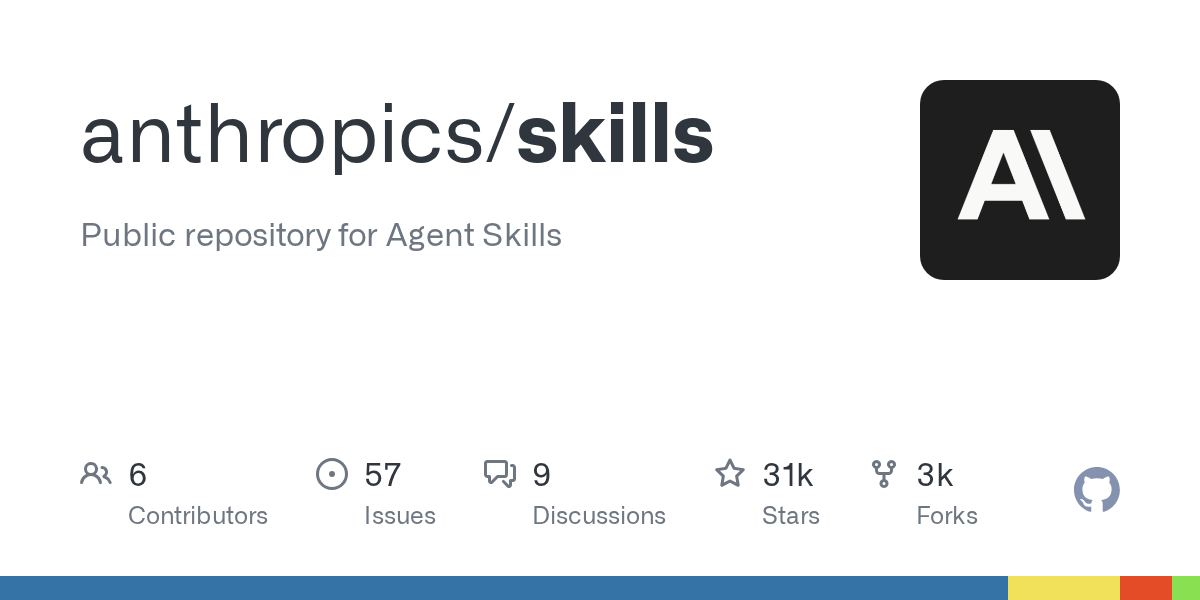
18. anthropics/skills
- 🏷️ 项目名称: anthropics/skills
- 🔗 项目地址: https://github.com/anthropics/skills
- ⭐ 当前 Star 数: 31044
- 📈 趋势 Star 数: 12035
- 📋 项目介绍: Public repository for Agent Skills
- 💡 推荐语: Anthropic官方开源AI智能体技能库,提供丰富的Python工具组件,助你快速构建功能强大的AI助手
数据来源

关于作者
📝 由 CoderJia 整理发布,助力开发者洞察技术趋势。
