博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅**感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。**🍅
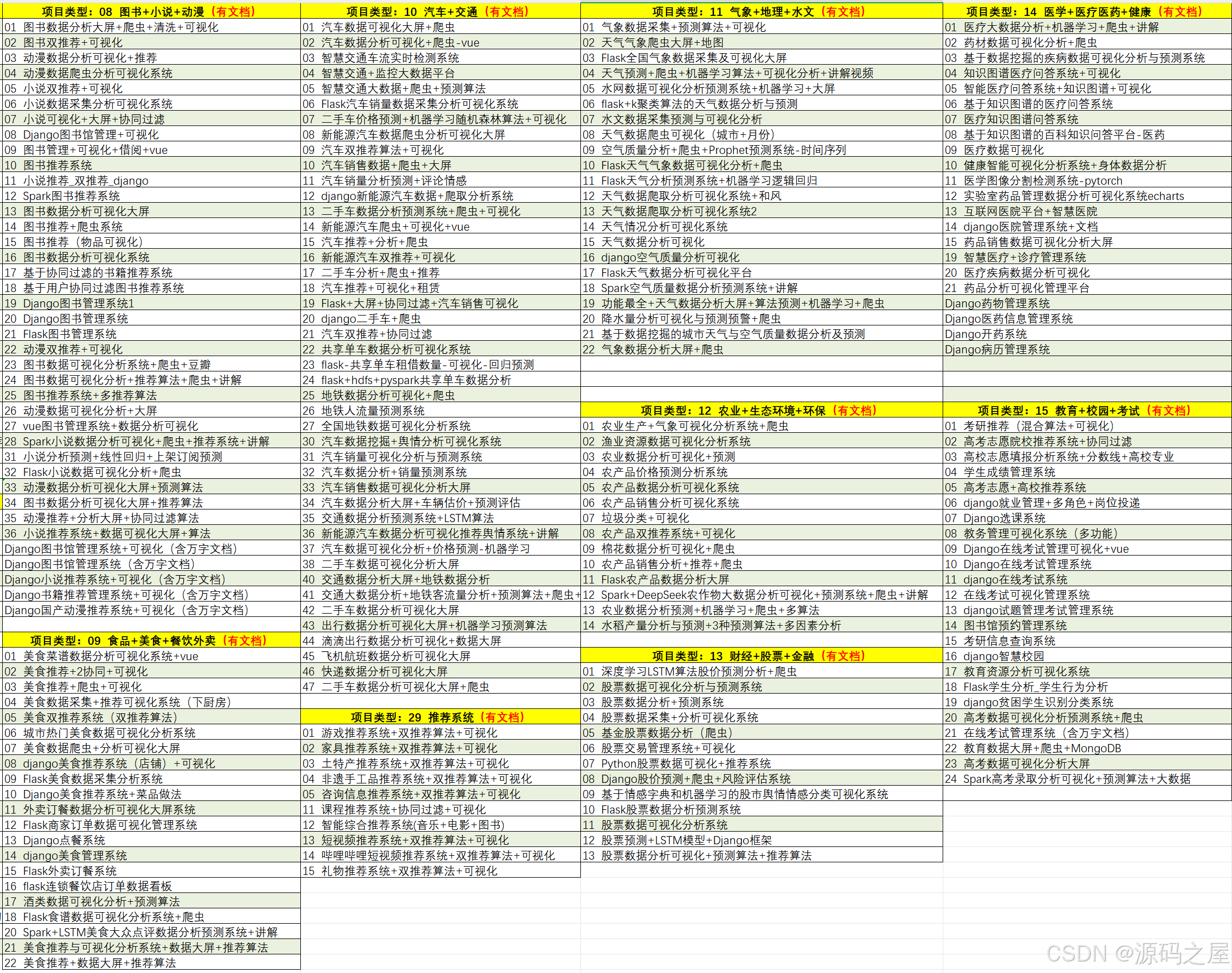
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
2、大数据毕业设计:2026年选题大全 深度学习 python语言 JAVA语言 hadoop和spark(建议收藏)✅
1、项目介绍
技术栈:Python 3.x、Django 5.0.7、MySQL、HTML5+CSS3+JavaScript、ECharts、SimpleUI、Pandas、PyEcharts、K-Means聚类、随机森林分类。
功能模块:
- 用户管理模块
- 数据可视化模块
- 分析预测模块
- 数据管理模块
- 后台管理模块
- 系统基础模块
项目介绍:城市居民出行模式可视化系统基于Django框架构建,专注于城市居民出行数据的分析与展示。系统采用MySQL存储出行数据,通过ECharts实现柱状图、饼图、折线图、散点图、环形图等多种图表可视化,集成K-Means聚类算法实现出行模式划分,利用随机森林分类算法完成出行方式预测。平台分为用户与管理员两种角色,提供数据查询、多维度可视化分析、出行预测、数据管理及权限控制等功能,可有效支持城市交通规划决策与出行规律研究。
2、项目界面
出行数据分析可视化
该页面为出行数据分析可视化大屏,通过柱状图、饼图、折线图等多种图表,从出发地、到达地、出行方式、出行时间等多个维度,直观呈现出行距离、时长、占比等多维度出行数据,实现出行数据的全局可视化分析与展示。
出行数据分析可视化
该页面为出行数据分析可视化系统的首页,顶部展示今日总出行次数、总行程距离、平均行程耗时、人均出行方式等核心运营指标并附环比变化,下方通过折线图呈现每日出行趋势分析,实现出行数据的概览与趋势可视化监控。
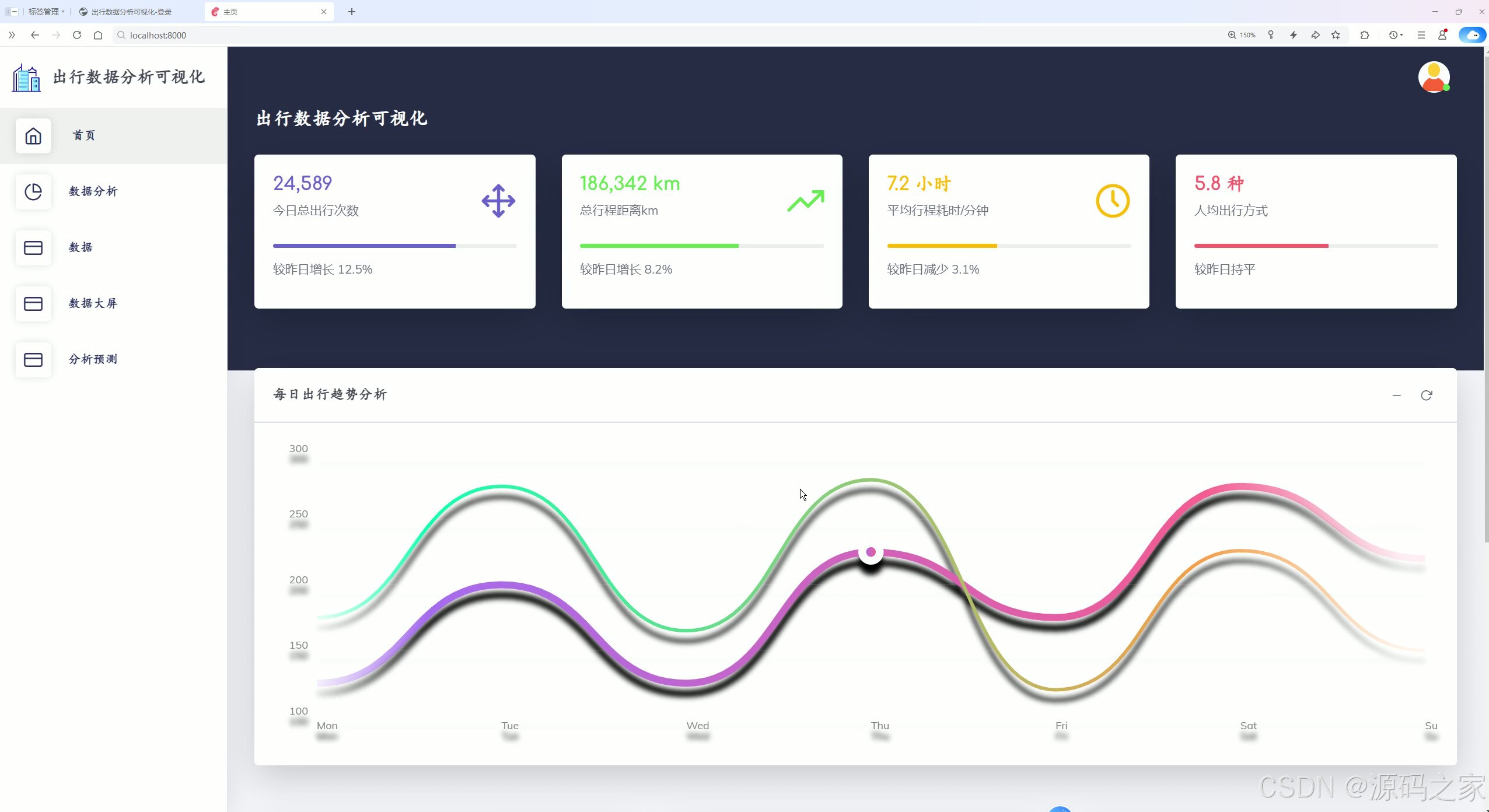
出行数据分析模块展示
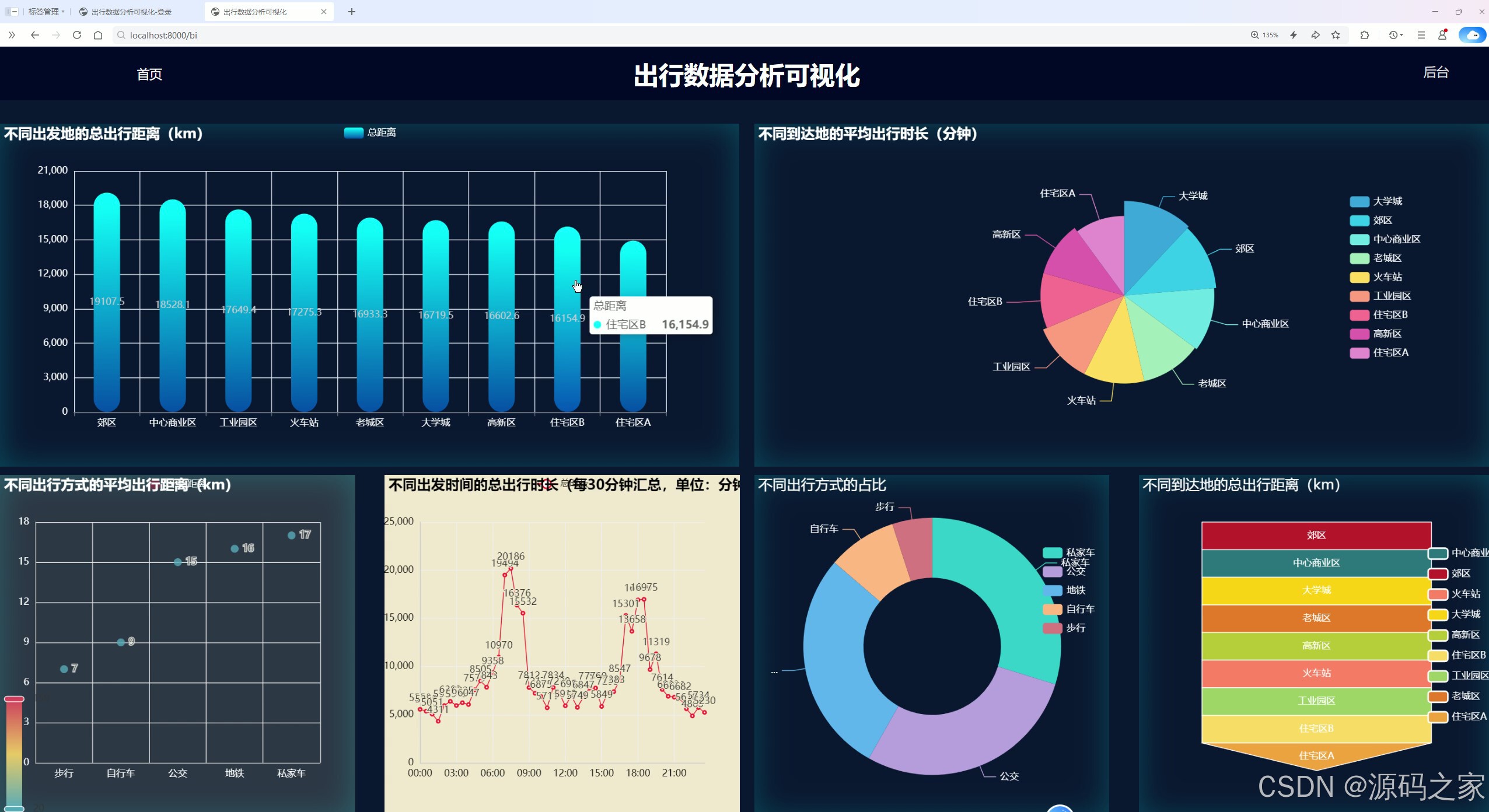
该页面作为出行数据分析可视化系统的核心展示大屏,整合了多维度出行数据统计、柱状图分析、饼图展示等功能模块,以直观图表呈现不同出发地的总出行距离、各区域到达地的平均出行时长等关键信息,实现对出行数据的全景式监控分析与结果展示。
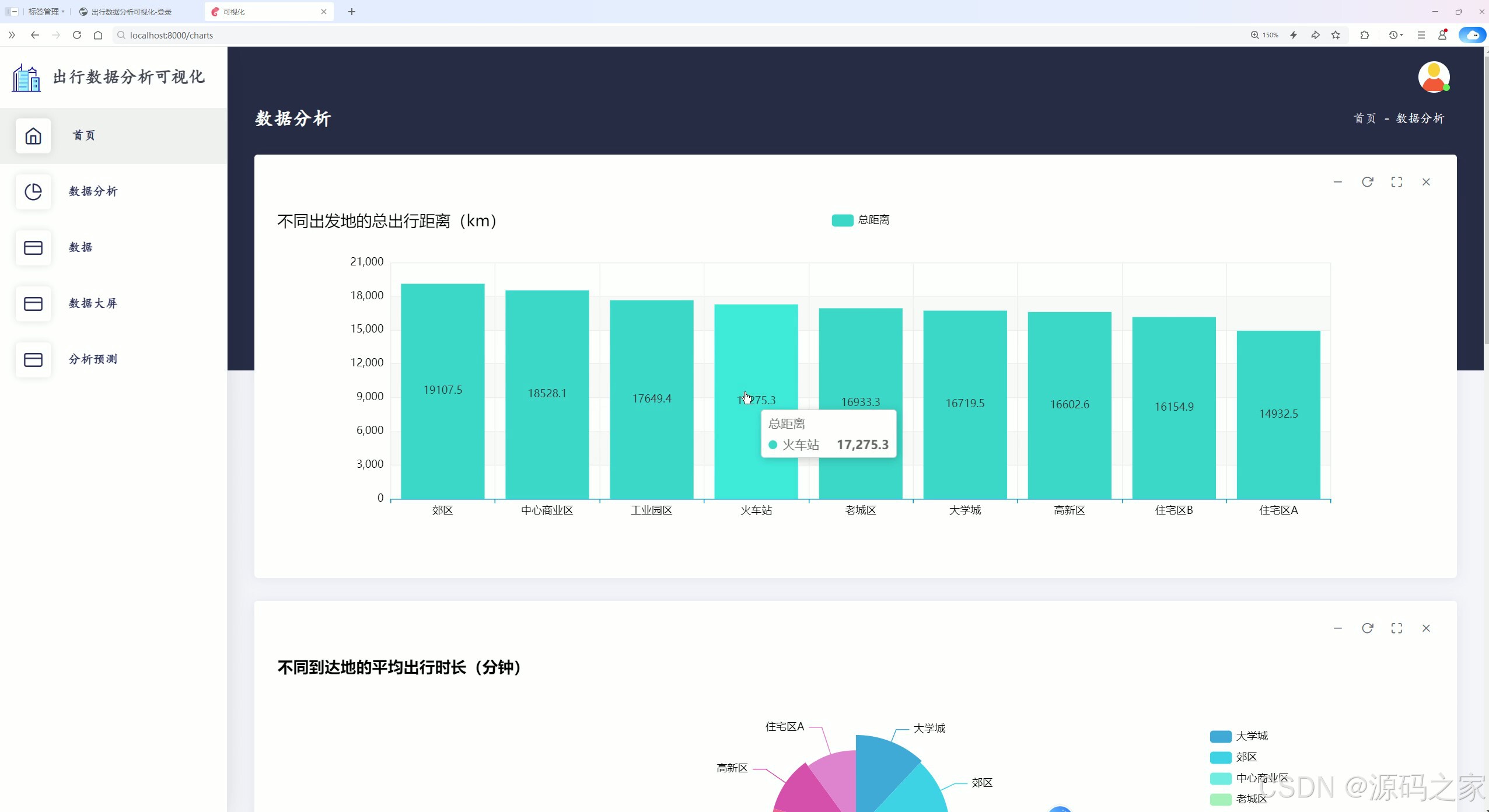
出行数据分析可视化页面
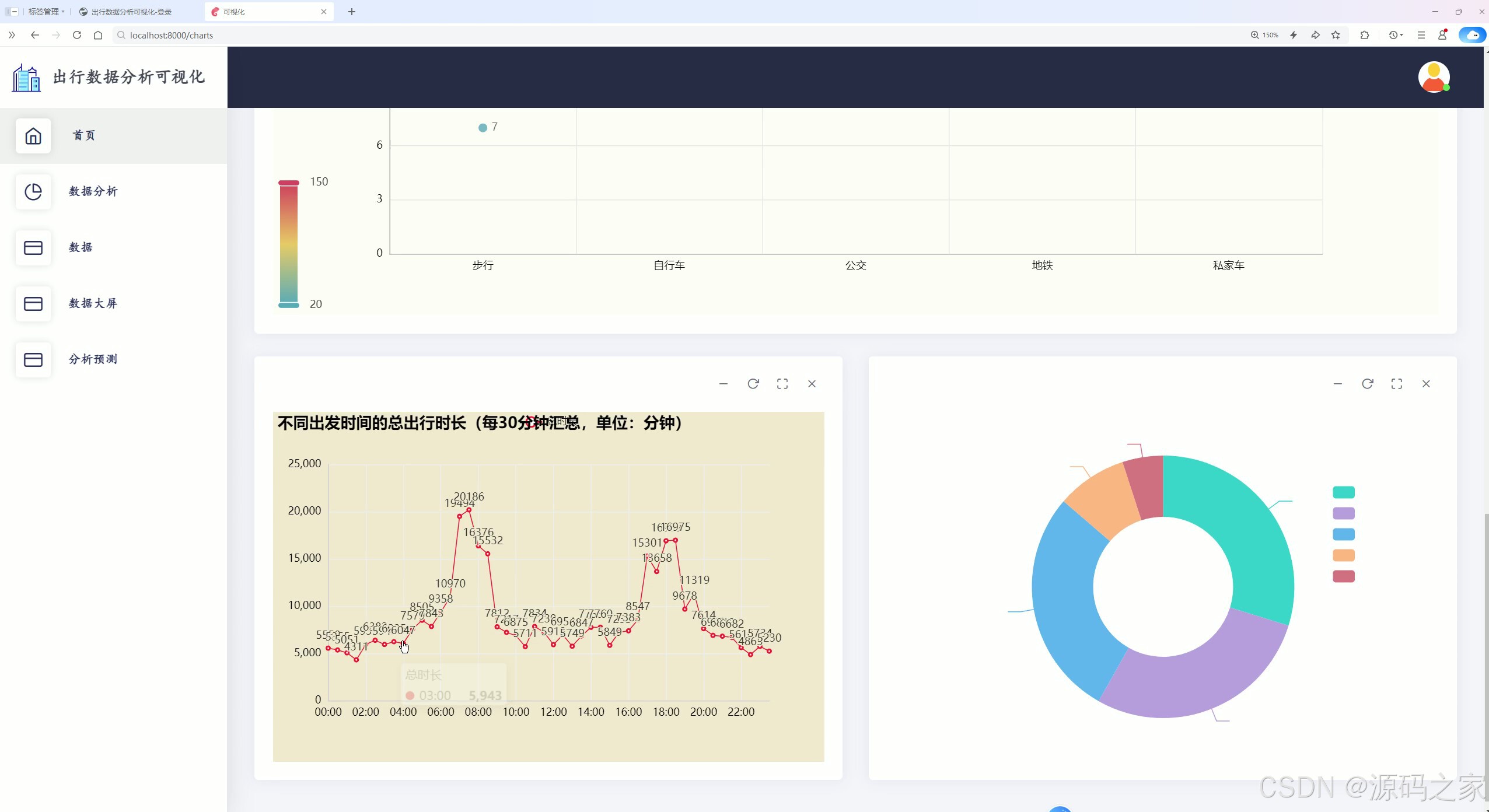
该页面为出行数据分析可视化系统的数据分析模块,通过散点图呈现不同出行方式的平均出行距离,以折线图展示不同出发时间的总出行时长变化趋势,用环形图呈现不同出行方式的占比情况,实现出行数据多维度的可视化分析与展示。
出行数据分析可视化数据查看页面
该页面为出行数据分析可视化系统的数据查看模块,提供字段筛选与筛选值输入功能,可按出发时间、出发地点等维度筛选出行数据,以表格形式展示出行相关明细数据,支持分页浏览,实现出行原始数据的查询、筛选与明细查看。
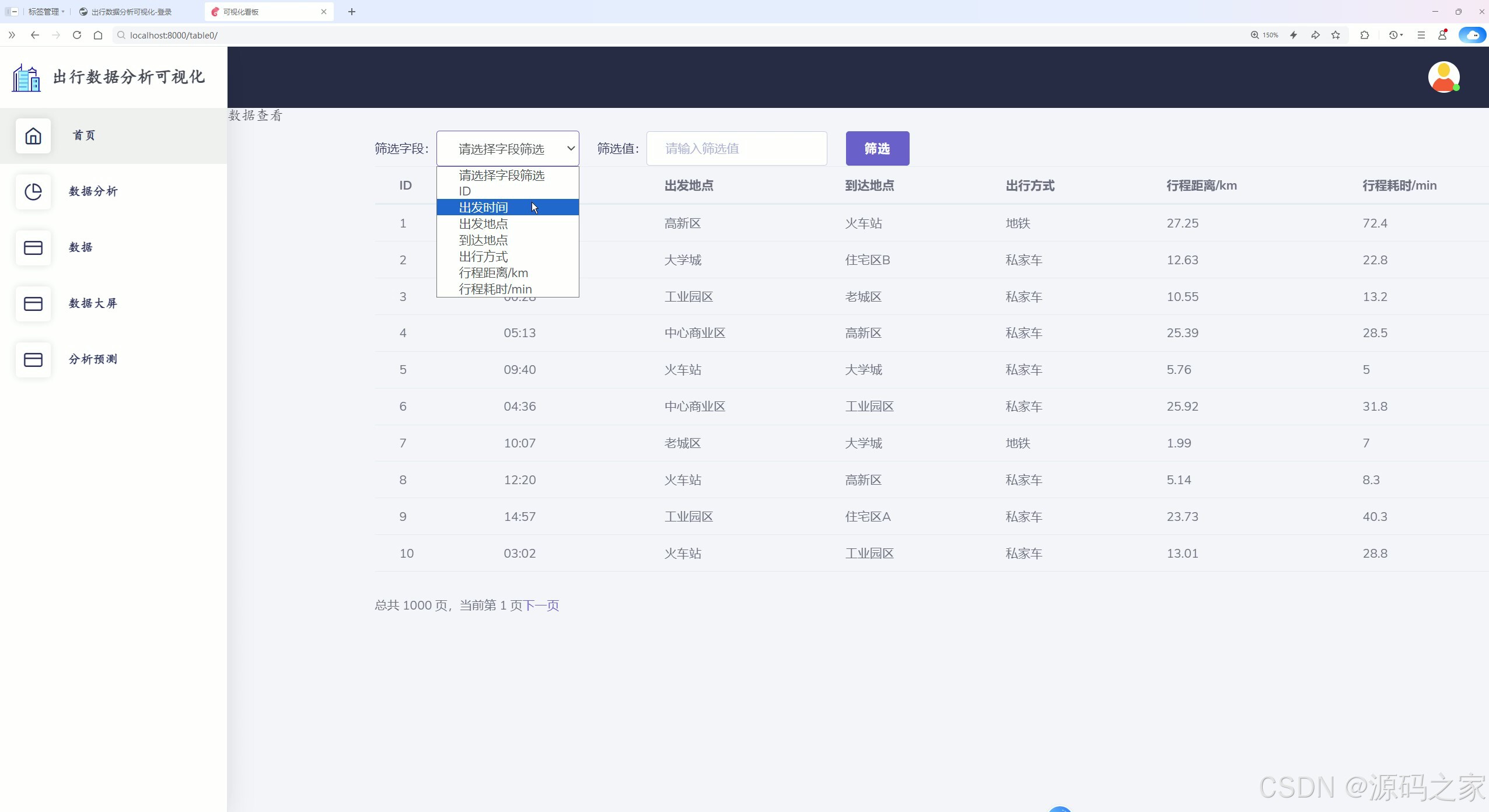
出行数据分析可视化预测页面
该页面为出行数据分析可视化系统的分析预测模块,提供出发时间、地点等出行信息的输入区域,支持提交分析出行模式,输出预测出行方式等分析结果,并以散点图呈现出行模式可视化内容,实现出行行为的预测分析与结果展示。
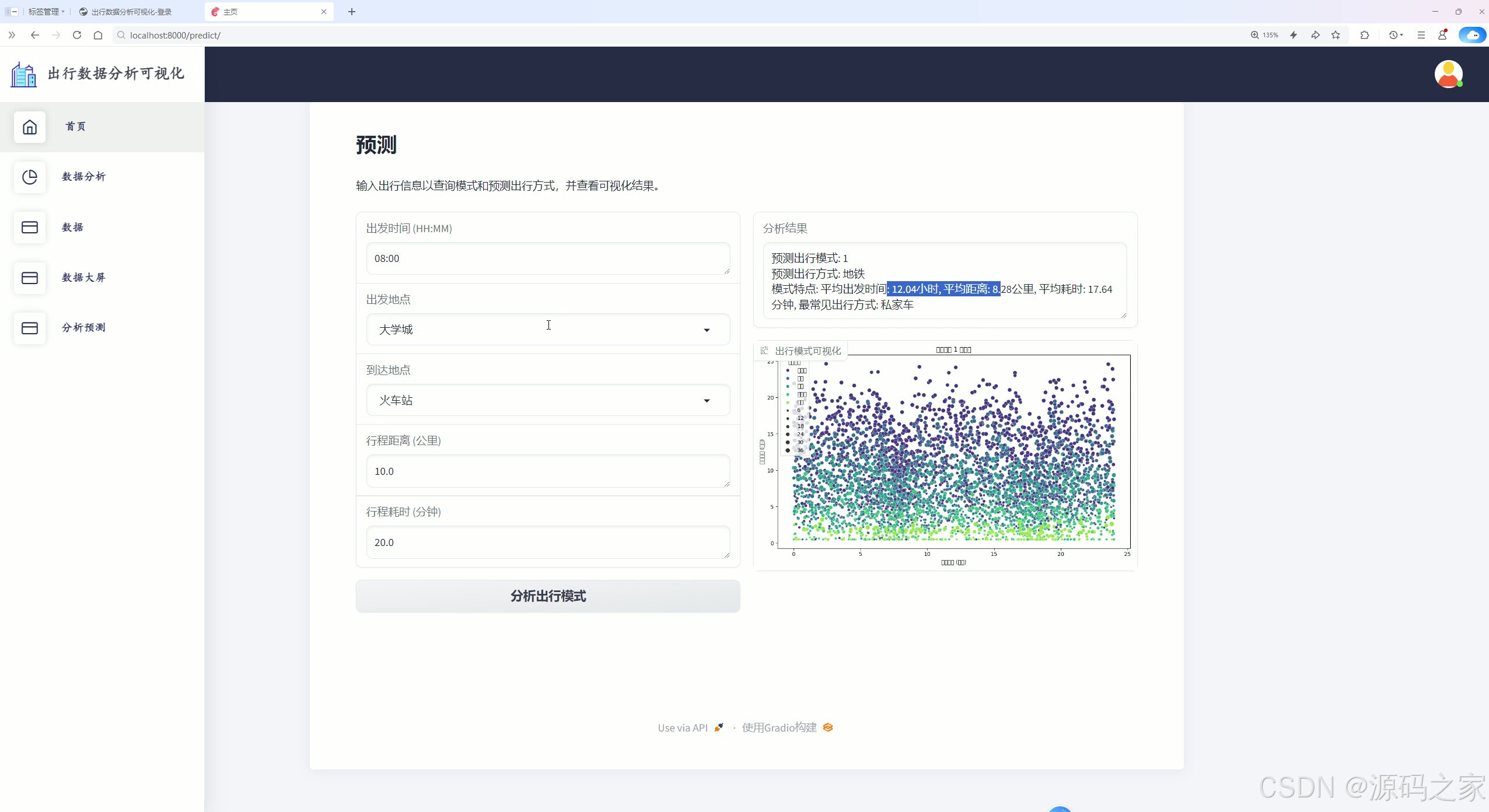
出行数据分析可视化登录页面
页面呈现的是一套用户身份验证与账号管理系统,包含登录、注册核心流程,支持输入用户名与密码进行身份核验,可注册新账号,同时集成了数据统计与业务管理功能,实现用户信息的有序管理与交互操作。
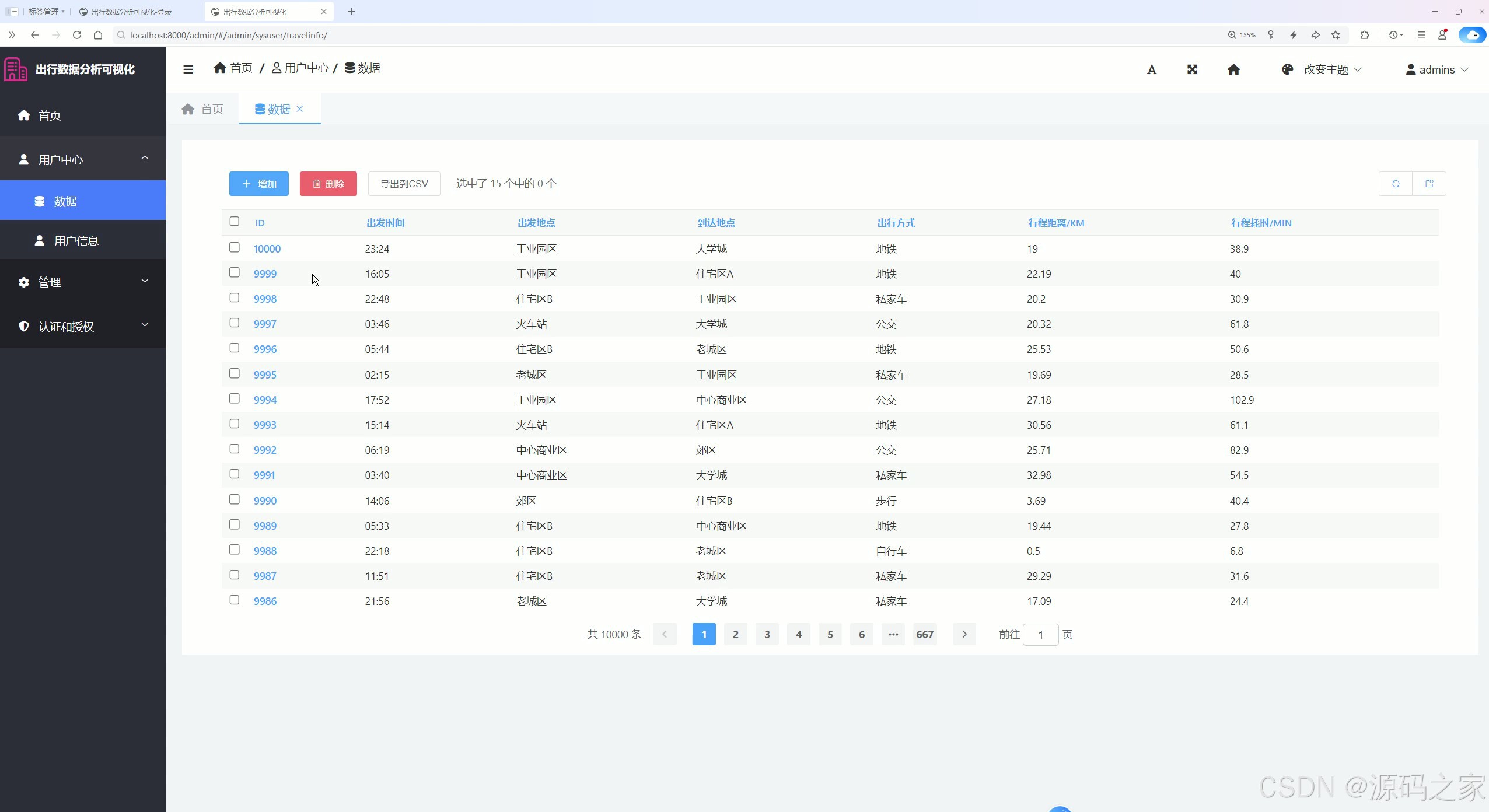
出行数据分析可视化后台数据管理页面
该页面为出行数据分析可视化系统的后台数据管理模块,以表格形式展示出行相关明细数据,提供增加、删除、导出到CSV等操作功能,支持分页浏览数据,实现出行原始数据的管理、维护与导出。
3、项目说明
一、技术栈简要说明
本系统后端采用Python 3.x语言与Django 5.0.7框架构建,利用其强大的ORM机制和路由系统完成业务逻辑处理与数据库交互。前端使用HTML5、CSS3和JavaScript实现页面布局与交互效果,结合ECharts图表库完成数据可视化渲染。数据库选用MySQL存储出行记录与用户信息。管理界面通过SimpleUI进行美化,提升后台操作体验。数据处理环节集成Pandas库进行数据清洗与转换,PyEcharts辅助生成可视化图表。算法层面引入K-Means聚类算法实现出行模式自动划分,采用随机森林分类算法完成出行方式的智能预测。
二、功能模块详细介绍
- 用户管理模块
该模块负责系统账号的全生命周期管理,支持用户注册、登录、注销以及个人信息维护。登录环节集成验证码验证机制,有效防范恶意登录行为。系统区分普通用户与管理员两种角色,普通用户可进行数据查询与预测分析,管理员则拥有数据管理和后台配置权限,实现差异化的访问控制。 - 数据可视化模块
作为系统的核心展示模块,通过柱状图、饼图、折线图、散点图、环形图、漏斗图等多种图表类型,从出发地分布、到达地分布、出行方式占比、出发时间规律、行程距离与耗时等多个维度进行数据呈现。模块提供数据大屏展示功能,顶部展示今日总出行次数、总行程距离、平均行程耗时、人均出行方式等核心指标并附环比变化,下方通过折线图监控每日出行趋势,实现出行数据的全局可视化分析与趋势监控。 - 分析预测模块
依托机器学习算法提供智能预测能力,用户可输入出发时间、出发地点、行程距离等信息,系统调用随机森林模型预测出行方式,同时运用K-Means聚类完成出行模式分类。预测结果以文本形式输出,并辅以散点图进行可视化呈现,帮助用户理解出行行为的潜在规律与分类特征。 - 数据管理模块
该模块面向管理员提供数据操作功能,以表格形式展示出行明细数据,支持按出发时间、出发地点等字段进行筛选查询。管理员可执行新增、删除数据记录的操作,并支持将数据导出为CSV文件,方便离线分析与备份。数据表格采用分页浏览机制,提升海量数据的管理效率。 - 后台管理模块
基于Django Admin框架并结合SimpleUI主题进行界面优化,提供用户中心、权限管理、认证授权等子功能。管理员可在后台对用户信息、系统日志、功能权限进行集中配置与管理,保障系统运行的规范性与安全性。 - 系统基础模块
包含页面导航栏、系统配置选项、主题样式切换、交互控件等基础功能,统一系统各页面的视觉风格与操作逻辑,确保用户在不同模块间切换流畅、交互响应稳定,为整体功能运行提供可靠的基础支撑。
三、项目总结
城市居民出行模式可视化系统是集数据管理、多维度可视化分析、机器学习预测于一体的综合性平台,针对城市交通出行场景提供了清晰的数据展示与智能分析能力。系统采用Django框架搭建整体架构,前端结合ECharts实现丰富的图表可视化,后端集成Pandas进行数据处理,并运用K-Means聚类与随机森林算法实现出行模式划分与出行方式预测。系统功能结构完整,包含用户管理、数据可视化、分析预测、数据管理、后台管理及系统基础六大模块,既满足普通用户对出行数据的查询、分析与预测需求,也支持管理员对数据和用户进行高效管理。整体系统界面简洁易用,部署简便,运行稳定,具备良好的扩展性与应用价值,能够为城市交通规划、出行规律研究及相关决策提供直观可靠的数据支持。
4、核心代码
1import gradio as gr 2import pandas as pd 3import numpy as np 4from sklearn.cluster import KMeans 5from sklearn.ensemble import RandomForestClassifier 6from sklearn.preprocessing import LabelEncoder 7from sklearn.model_selection import train_test_split 8import matplotlib.pyplot as plt 9import seaborn as sns 10 11# 假设数据已转换为DataFrame格式 12data = pd.read_csv("../数据.csv") 13# 数据预处理 14le_departure = LabelEncoder() 15le_arrival = LabelEncoder() 16le_mode = LabelEncoder() 17 18data['出发地点'] = le_departure.fit_transform(data['出发地点']) 19data['到达地点'] = le_arrival.fit_transform(data['到达地点']) 20data['出行方式'] = le_mode.fit_transform(data['出行方式']) 21 22# 将时间转换为小时格式 23data['出发小时'] = data['出发时间'].apply(lambda x: int(x.split(':')[0]) + int(x.split(':')[1]) / 60) 24 25# 特征工程 26features = data[['出发小时', '出发地点', '到达地点', '行程距离', '行程耗时']] 27travel_mode = data['出行方式'] 28 29# K-means聚类分析出行模式 30kmeans = KMeans(n_clusters=4, random_state=42) 31data['出行模式'] = kmeans.fit_predict(features) 32 33# 训练随机森林模型预测出行方式 34X_train, X_test, y_train, y_test = train_test_split(features, travel_mode, test_size=0.2, random_state=42) 35rf_model = RandomForestClassifier(n_estimators=100, random_state=42) 36rf_model.fit(X_train, y_train) 37 38# 可视化函数 39def plot_travel_patterns(cluster): 40 cluster_data = data[data['出行模式'] == cluster] 41 plt.figure(figsize=(10, 6)) 42 sns.scatterplot(x='出发小时', y='行程距离', hue=le_mode.inverse_transform(cluster_data['出行方式']), 43 size=cluster_data['行程耗时'], data=cluster_data, palette='viridis') 44 plt.title(f'出行模式 {cluster} 可视化') 45 plt.xlabel('出发时间 (小时)') 46 plt.ylabel('行程距离 (公里)') 47 plt.legend(title='出行方式') 48 plt.tight_layout() 49 return plt 50 51# 查询和预测函数 52def analyze_travel(departure_time, departure_loc, arrival_loc, distance, duration): 53 # 转换为数值 54 dep_hour = int(departure_time.split(':')[0]) + int(departure_time.split(':')[1]) / 60 55 dep_loc = le_departure.transform([departure_loc])[0] 56 arr_loc = le_arrival.transform([arrival_loc])[0] 57 input_features = np.array([[dep_hour, dep_loc, arr_loc, float(distance), float(duration)]]) 58 59 # 预测出行模式和方式 60 cluster = kmeans.predict(input_features)[0] 61 predicted_mode = le_mode.inverse_transform(rf_model.predict(input_features))[0] 62 63 # 生成可视化 64 plot = plot_travel_patterns(cluster) 65 66 # 返回结果 67 return (f"预测出行模式: {cluster}\n预测出行方式: {predicted_mode}\n" 68 f"模式特点: {describe_cluster(cluster)}"), plot 69 70# 描述每个聚类的特点 71def describe_cluster(cluster): 72 cluster_data = data[data['出行模式'] == cluster] 73 avg_time = cluster_data['出发小时'].mean() 74 avg_distance = cluster_data['行程距离'].mean() 75 avg_duration = cluster_data['行程耗时'].mean() 76 common_mode = le_mode.inverse_transform([cluster_data['出行方式'].mode()[0]])[0] 77 return (f"平均出发时间: {avg_time:.2f}小时, 平均距离: {avg_distance:.2f}公里, " 78 f"平均耗时: {avg_duration:.2f}分钟, 最常见出行方式: {common_mode}") 79 80# Gradio界面 81with gr.Blocks(title="预测") as demo: 82 gr.Markdown("# 预测") 83 gr.Markdown("输入出行信息以查询模式和预测出行方式,并查看可视化结果。") 84 85 with gr.Row(): 86 with gr.Column(): 87 departure_time = gr.Textbox(label="出发时间 (HH:MM)", value="08:00") 88 departure_loc = gr.Dropdown(label="出发地点", choices=list(le_departure.classes_)) 89 arrival_loc = gr.Dropdown(label="到达地点", choices=list(le_arrival.classes_)) 90 distance = gr.Textbox(label="行程距离 (公里)", value="10.0") 91 duration = gr.Textbox(label="行程耗时 (分钟)", value="20.0") 92 submit_btn = gr.Button("分析出行模式") 93 94 with gr.Column(): 95 output_text = gr.Textbox(label="分析结果") 96 output_plot = gr.Plot(label="出行模式可视化") 97 98 submit_btn.click( 99 fn=analyze_travel, 100 inputs=[departure_time, departure_loc, arrival_loc, distance, duration], 101 outputs=[output_text, output_plot] 102 ) 103 104demo.launch() 105 106
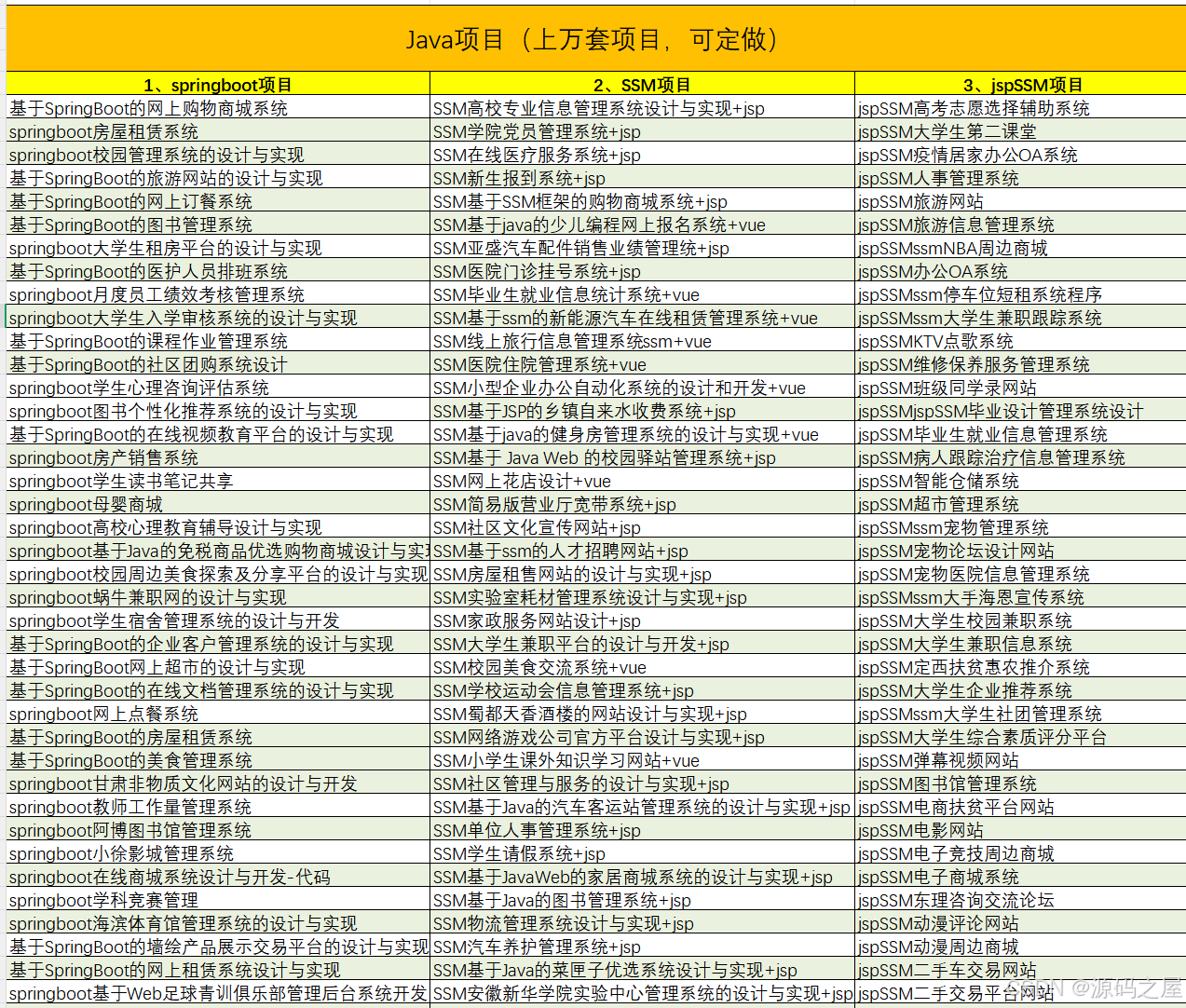
5、项目列表



6、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻
《计算机毕业设计:Python出行数据智能分析与预测平台 Django框架 可视化 数据分析 PyEcharts 交通 深度学习(建议收藏)✅》 是转载文章,点击查看原文。
